NVIDIA DGX
- AI/ディープラーニング

AI・ディープラーニングに不可欠なシステム、NVIDIA DGXは、最新のBlackwellアーキテクチャGPUとGPU最適化ソフトウェアを統合し、ペタFLOPS級の性能と簡素化された管理を提供します。モデル開発から推論、運用まで、AIファクトリーを支える次世代プラットフォームです。
Grace Blackwellアーキテクチャ搭載
ペタFLOPS級のAI性能をコンパクトに
NVIDIA DGX Spark
NVIDIA DGX Sparkは、NVIDIA GB10 Grace Blackwell Superchipを搭載した世界最小クラスのAIスーパーコンピューターです。128GBの統合メモリと最大1ペタFLOPSのAI演算性能により、生成AIや大規模言語モデル(LLM)のプロトタイピング、ファインチューニング、推論をデスクトップ環境で実現します。NVIDIA AIソフトウェアスタックをプリインストールし、クラウド依存からの脱却、機密データの安全なローカル処理を可能にします。
Grace Blackwell Superchipによる高性能処理
CPUとGPUを統合したGB10 Superchipが、FP4精度で最大1ペタFLOPSのAI性能を発揮します。コンパクトな筐体で、従来クラウドでしか扱えなかった規模のモデルをローカルで実行可能になります。

128GB統合メモリとスケーラブル設計
CPUとGPUが共有する128GB LPDDR5xメモリにより、最大2000億パラメータのモデルを推論。
ConnectX-7ネットワークで2台接続すれば、最大4000億パラメータのモデルにも対応します。
NVIDIA DGX Spark スペック表
| アーキテクチャ | NVIDIA Grace Blackwell |
|---|---|
| GPU | NVIDIA Blackwell アーキテクチャ |
| CPU | 20コア Arm(10 Cortex-X925 + 10 Cortex-A725) |
| Tensorコア | 第5世代(FP4対応) |
| AI性能 | 最大 1,000 AI TOPS(FP4演算) |
| システムメモリ | 128GB LPDDR5x 統合メモリ |
| メモリ帯域幅 | 273GB/s |
| ストレージ | 4TB NVMe M.2(自己暗号化機能付き) |
| ネットワーク | 10GbE + ConnectX-7 Smart NIC |
| USBポート | USB Type-C ×4 |
| 無線 | Wi-Fi 7 / Bluetooth 5.3 |
| 映像出力 | HDMI 2.1a |
| OS | NVIDIA DGX OS |
| 外形寸法 | 150mm × 150mm × 50.5mm |
| 重量 | 約1.2kg |
Blackwell Ultra GPU搭載
LLM推論と生成AIを加速する次世代AIインフラ
NVIDIA DGX B300
NVIDIA DGX B300は、8基のBlackwell Ultra GPUと2.3TBのGPUメモリを搭載した、AIファクトリー時代のための統合プラットフォームです。FP4精度で最大144ペタFLOPSの推論性能、FP8精度で72ペタFLOPSのトレーニング性能を実現し、前世代比で推論性能は最大11倍、学習性能は4倍向上。NVIDIA AI EnterpriseとMission Controlを標準搭載し、モデル開発から運用までを一貫してサポート。最新のデータセンター設計に最適化されたフォームファクターで、柔軟な導入とスケーラブルなAIインフラ構築を可能にします。
圧倒的なAI性能と大容量メモリ
Blackwell Ultra GPU ×8基、合計2.3TBのGPUメモリを搭載。LLMや生成AIモデルのトレーニング・推論をリアルタイムで処理し、ハイパースケーラー級の性能を企業に提供します。

データセンター統合と運用効率化
NVIDIA MGXラック対応の新フォームファクターで、既存インフラに容易に統合可能。Mission ControlによるAIワークロードのオーケストレーションで、運用の複雑さを排除し、スピードと効率を最大化します。
NVIDIA DGX B300 スペック表
| アーキテクチャ | NVIDIA Grace Ultra | |
|---|---|---|
| GPU | NVIDIA Blackwell Ultra GPU ×8 | |
| CPU | Intel Xeon 6776P | |
| Tensorコア | 第5世代(FP4対応) | |
| AI性能 | FP4推論:144 PFLOPS / FP8学習:72 PFLOPS | |
| メモリ帯域幅 | NVLink 14.4 TB/s(NVSwitch ×2) | |
| ストレージ | OS:2×1.9TB NVMe M.2 / 内部:8×3.84TB NVMe E1.S | |
| ネットワーク | 8×OSFP(最大800Gb/s)/ 2×QSFP112(最大400Gb/s) | |
| USBポート | USB Type-C ×4 | |
| OS | NVIDIA DGX OS | |
| 外形寸法 | ラックサイズ:10U | |
| 重量 | 約200kg(推定) | |
Blackwell GPU搭載
生成AIとLLMを加速する統合AIプラットフォーム
NVIDIA DGX B200
NVIDIA DGX B200は、8基のBlackwell GPUと最大1.44TBのGPUメモリを搭載した次世代AIスーパーコンピューターです。FP4精度で144ペタFLOPS、FP8精度で72ペタFLOPSの演算性能を誇り、前世代比で推論性能は最大15倍、トレーニング性能は3倍に向上。NVIDIA AI EnterpriseとMission Controlを標準搭載し、開発から運用までのAIパイプラインを一貫してサポートします。
圧倒的なAI性能とメモリ帯域
Blackwell GPU ×8基、合計1.44TBのGPUメモリ、64TB/sの帯域幅で、LLMや生成AIモデルを高速処理。大規模データセットのトレーニングからリアルタイム推論まで、企業のAI導入を加速します。
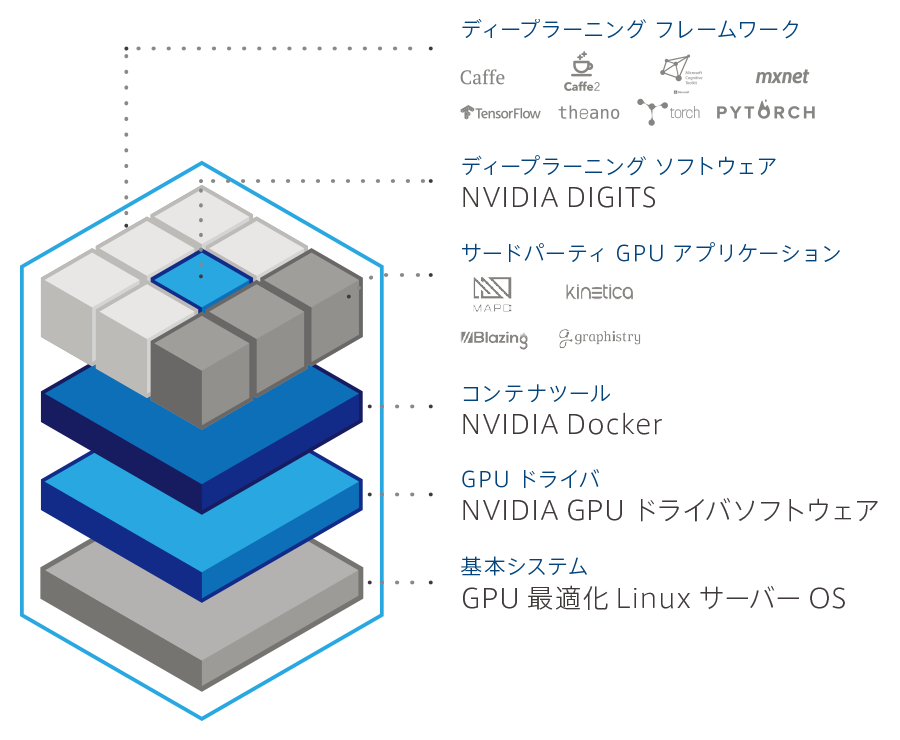
データセンター統合と運用効率化
NVIDIA NVSwitchと第5世代NVLinkによる14.4TB/sの総帯域幅でGPU間通信を最適化。Mission ControlによるAIワークロードのオーケストレーションで、スケーラブルなAIインフラを簡易構築します。
NVIDIA DGX B200 スペック表
| アーキテクチャ | NVIDIA Blackwell | |
|---|---|---|
| GPU | NVIDIA Blackwell GPU ×8 | |
| CPU | Intel Xeon Platinum 8570 ×2(合計112コア) | |
| Tensorコア | 第5世代(FP4対応) | |
| AI性能 | FP4推論:144 PFLOPS / FP8学習:72 PFLOPS | |
| システムメモリ | 2TB(最大4TBまで拡張可能) | |
| メモリ帯域幅 | GPU間:64TB/s(HBM3e)/ NVLink総帯域:14.4TB/s | |
| ストレージ | OS:2×1.9TB NVMe M.2 / 内部:8×3.84TB NVMe E1.S | |
| ネットワーク | 4×OSFP(最大400Gb/s)/ 2×QSFP112(BlueField-3 DPU 最大400Gb/s) | |
| OS | NVIDIA DGX OS / Ubuntu | |
| 外形寸法 | ラックサイズ:10U | |
| 重量 | 約200kg(推定) | |
H200 Tensor Core GPU搭載
生成AIとLLMを加速する究極のAIインフラ
NVIDIA DGX H200
NVIDIA DGX H200は、8基のH200 Tensor Core GPUと合計1,128GBのGPUメモリを搭載した、AIファクトリー時代のためのハイエンドプラットフォームです。FP8精度で32ペタFLOPSの演算性能を誇り、前世代比でネットワーク性能は2倍、スケーラビリティも大幅に向上。NVIDIA AI EnterpriseとBase Commandを標準搭載し、生成AI、LLM、ディープラーニングなどの大規模ワークロードをオンプレミスで実現します。
Hopperアーキテクチャによる圧倒的性能
H200 GPUは141GBのHBM3eメモリを搭載し、4.8TB/sの帯域幅を実現。LLMや生成AIの推論・学習を高速化し、H100比で推論性能は最大2倍向上します。

データセンター統合と運用効率化
4基のNVSwitchによるGPU間7.2TB/sの帯域幅と、ConnectX-7ネットワークで最大1TB/sの双方向通信を実現。Base Commandによるオーケストレーションで、複雑なAIワークロードを効率的に管理します。
NVIDIA DGX H200 スペック表
| アーキテクチャ | NVIDIA Hopper | |
|---|---|---|
| GPU | NVIDIA H200 Tensor Core GPU ×8 | |
| CPU | Intel Xeon Platinum 8480C ×2(合計112コア) | |
| Tensorコア | 第4世代(FP8対応) | |
| AI性能 | FP8:32 PFLOPS | |
| システムメモリ | 2TB | |
| メモリ帯域幅 | GPU間:7.2TB/s(NVSwitch)/ GPUメモリ:4.8TB/s | |
| ストレージ | OS:2×1.9TB NVMe M.2 / 内部:8×3.84TB NVMe U.2 | |
| ネットワーク | 4×OSFP(最大400Gb/s)/ 2×QSFP112(最大400Gb/s) | |
| OS | NVIDIA DGX OS / Ubuntu / RHEL / Rocky | |
| 外形寸法 | ラックサイズ:10U | |
| 重量 | 約130kg | |
| 消費電力 | 最大10.2kW | |
AIインフラストラクチャの金字塔
NVIDIA DGX H100
DGX H100は、世界初の専用AIインフラストラクチャの第4世代であり、完全に最適化されたハードウェアおよびソフトウェア・プラットフォームです。新しいNVIDIA AIソフトウェア・ソリューションに対応し、多様なサードパーティのサポートを受けられるエコシステムを利用でき、NVIDIAプロフェッショナル・サービスによりエキスパートからのアドバイスを受けることができます。
大規模なワークロードに対応できるように強化されています
NVIDIA DGX H100は、6倍高速なパフォーマンス、2倍高速なネットワーキング、およびハイスピードなスケーラビリティをNVIDIA DGX SuperPODに対して発揮します。この次世代アーキテクチャは、自然言語処理やディープラーニングによるレコメンデーション・モデルといった大規模なワークロードに対応できるように強化されています。
思いのままに使えるインフラストラクチャ
DGX H100は、オンプレミスにインストールして直接管理したり、NVIDIA DGX対応のデータ センターでの設置、NVIDIA認定のマネージド・サービス・プロバイダーを通じてアクセスすることもできます。また、 DGX対応のライフサイクル管理により、組織は予測性の高い財務モデルを入手して、最先端のデプロイメントを維持できます。
NVIDIA DGX H100 スペック表
| アーキテクチャ | NVIDIA Hopper | |
|---|---|---|
| GPU | NVIDIA H100 Tensor Core GPU 80GB x8 | |
| CPU | Intel Xeon Platinum 8480C ×2(合計112コア、2.0GHzベース、最大3.8GHz) | |
| Tensorコア | 第4世代(FP8対応) | |
| AI性能 | FP8:32 PFLOPS | |
| システムメモリ | 2TB | |
| ストレージ | OS:1.92TB NVMe M.2 ×2 内部:3.84TB NVMe U.2 ×8 |
|
| ネットワーク | 4×OSFPポート(ConnectX-7 VPI 最大400Gb/s)/ 2×デュアルポート ConnectX-7 VPI(最大400Gb/s) | |
| OS | NVIDIA DGX OS / Ubuntu / RHEL / Rocky | |
| 外形寸法 | 高さ:356mm × 幅:482.2mm × 奥行:897.1mm | |
| 重量 | 約130kg | |
| 消費電力 | 最大10.2kW | |

